

 Abstract
Abstract HTML
HTML Reference
Reference Related
Related PDF
PDF










-
Since the initial detection of gravitational waves (GWs) stemming from binary black hole (BBH) mergers [1] and a binary neutron star (BNS) event [2–4], the LIGO-Virgo-KAGRA collaboration [5–7] has reported the detections of over 90 GW events involving compact binary coalescences. These GW observations play a pivotal role in advancing fundamental physics [8–13], astrophysics [14–19], and cosmology [20–37]. However, it is important to note that GW data are susceptible to non-Gaussian noise contamination [38–41], which potentially influences the aforementioned scientific analyses.
Non-Gaussian noise, referred to as glitches and non-stationary noise, poses a challenge due to it contaminating GW data, thereby impacting the quest for GW signals and the accurate estimation of wave source parameters [41–46]. Various sources contribute to glitches, including seismic events such as earthquakes [47] and environmental factors like passing trains [48]. While numerous techniques are presently employed to mitigate glitches at their source [49–52], future observations operating at heightened sensitivities are anticipated to yield increased detection rates [53–55]. Consequently, the reduction of GW signals tainted by glitches becomes a challenging task [56].
During the recent third LIGO-Virgo observing run (O3), 24% of the GW candidates were found to be contaminated by glitches [39, 40]. Notably, the analyses of prominent events like GW170817, GW200129, and GW191109_010717 were substantially impacted due to glitches [11, 57–59]. Therefore, effective glitch mitigation strategies are imperative prior to undertaking parameter estimation.
The two primary methods commonly employed for complete glitch removal are BayesWave [60, 61] and gwsubtract [62, 63]. Additionally, various approaches exist for mitigating the effects of glitches in observational data [46, 64–70]. However, as of O3, there remains a lack of reasonably low-latency methods for data cleaning [42], posing a potential hindrance to the discovery of certain physical phenomena, such as the observation of subsequent electromagnetic (EM) counterparts following BNS mergers. This challenge arises from the computational intensity of the full Bayesian approach, making it a time-consuming process. Consequently, there is a pressing need to develop precise and low-latency deglitching methods.
One prevalent technique for alleviating the impact of corrupted glitches is gating [71], enabling the prompt removal of glitch-affected data with low latency [72]. A notable case is the handling of GW170817, for which contaminated segments of the data were excised to facilitate the search for EM counterparts [57]. However, the confluence of gating and signals in the time-frequency domain poses challenges to parameter inference [57]. Machine learning emerges as a promising solution for addressing this issue, given its non-linear GPU-based computational capabilities, making it well-suited for the low-latency processing of non-stationary data [73]. In addition, the robustness of machine learning also makes it more suitable for processing GW data contaminated by glitches [74–77].
Several studies have explored the application of machine learning in reconstructing glitches from data, enabling subsequent subtraction to mitigate their effects [78–84]. Following the acquisition of clean data, additional computations are often necessary for deriving source parameters for subsequent analyses [85]. Consequently, we aim to address the query of whether machine learning can be effectively employed to directly infer GW parameters from contaminated data.
Neural posterior estimation [86–89], relying on a normalizing flow, demonstrates a precise estimation of the posterior distribution of the source parameters [90–92]. Functioning as a likelihood-free method, a normalizing flow proves effective in handling non-Gaussian data, exemplified by its successful application to the 21 cm signal [93–96]. Consequently, our exploration aims to ascertain the viability of employing a normalizing flow in the processing of GW data contaminated by glitches.
In this study, we introduce a novel method grounded in a normalizing flow for parameter estimation for data afflicted by glitches. While utilizing time-frequency domain data proves advantageous for glitch-contaminated data [97–99], inherent limitations in the time-frequency resolution and binning may result in the loss of intricate details, thereby influencing the parameter inference. In recent years, some researchers have studied improvements of the network performance from the data fusion of time series and corresponding frequency domain data [100–102]. Therefore we employ a dual approach, incorporating both time-domain and time-frequency domain data in the parameter inference process, i.e., temporal and time-spectral fusion normalizing flow (TTSF-NF). Our investigation specifically targets high signal-to-noise ratio (SNR) glitches that defy resolution through robustness.
The organization of this work is as follows: Section II provides an introduction to the methodology employed. In Section III, we comprehensively present the results yielded by our approach. The conclusion is encapsulated in Section IV.
-
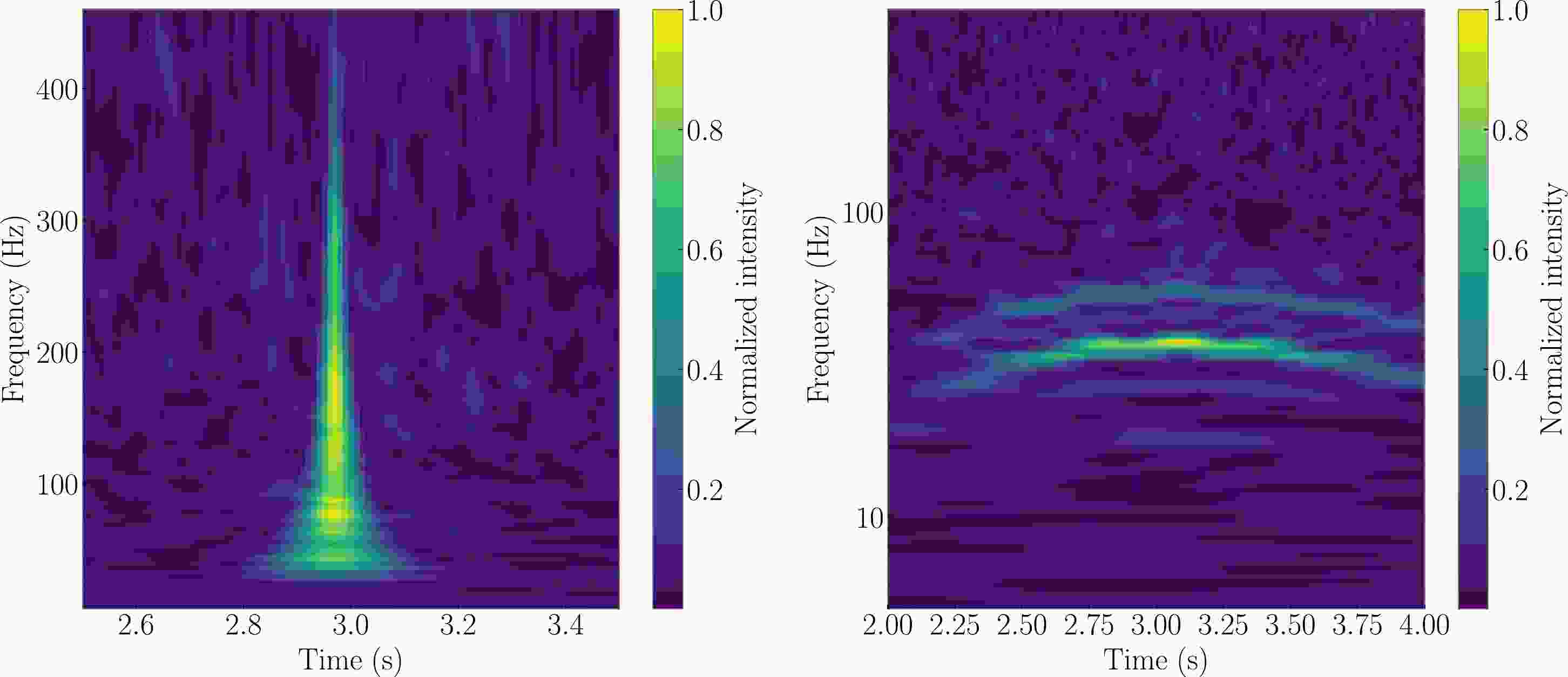
In this study, we focused on two prevalent glitches commonly observed in aLIGO detectors — namely, “blip” and “scattered light”— both sourced from Gravity Spy [103]. The spectrogram diagrams for each glitch are illustrated in Fig. 1. Our glitch selection specifically targeted segments with an SNR exceeding 12, a criterion chosen due to the prevalent focus of existing research on scenarios with a relatively low SNR [46, 104]. As depicted in Fig. 2, relying solely on the robustness of the time normalizing flow (T-NF) proves insufficient for resolving this challenge. Notably, in the case of Hanford's blip during O3b, the proportion of data with
$ {\rm{SNR}}>12 $ is 54%. This underscores the likelihood of encountering simultaneous occurrences of a signal and a high SNR glitch in future observations.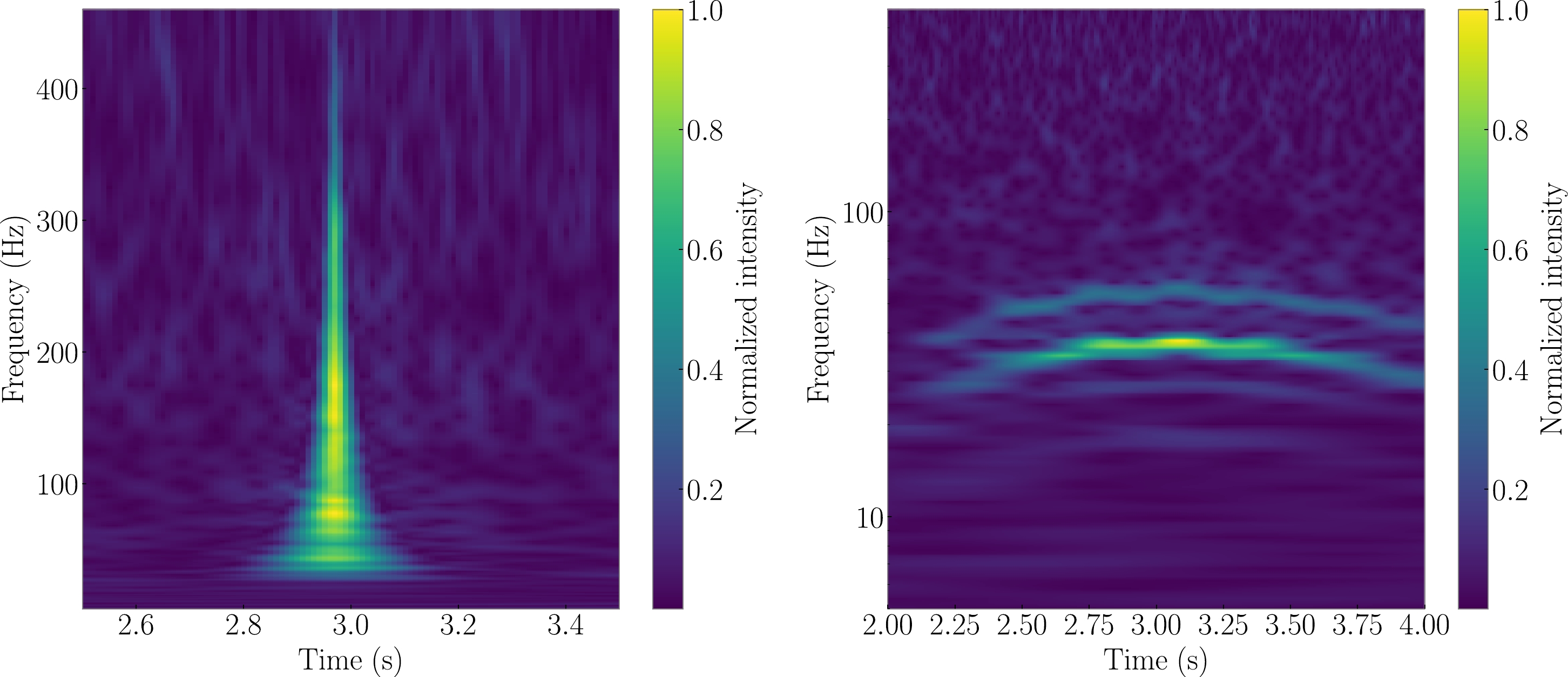
Figure 1. (color online) Two types of glitches considered in this work. Left panel: Blip noise characterized by durations on the order of milliseconds and a broad frequency bandwidth on the order of 100 Hz. Right panel: scattered light noise which persists for an extended duration and exhibits a frequency below 100 Hz.
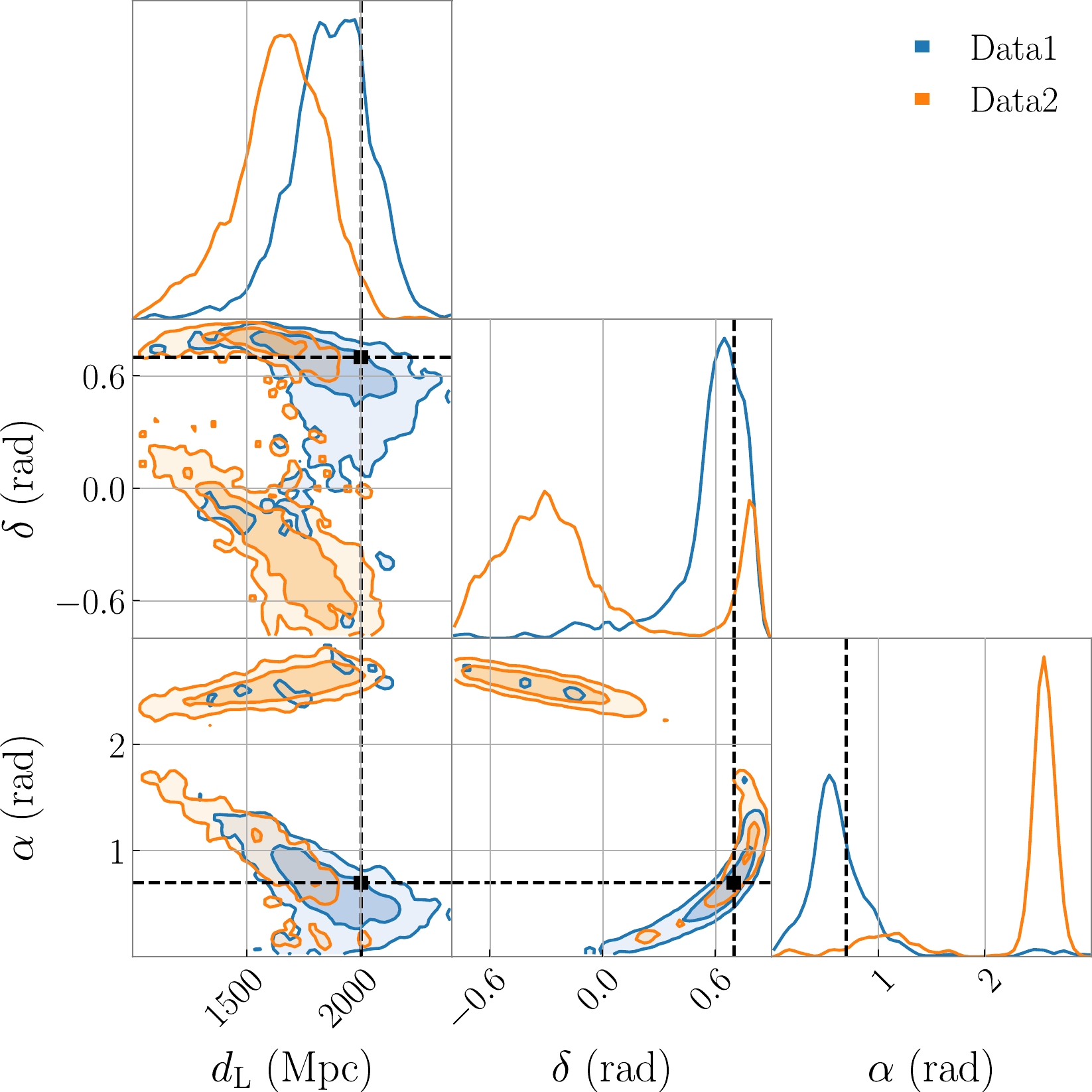
Figure 2. (color online) One- and two-dimensional marginalized posterior distributions for
$ d_{{\rm{L}}} $ , δ, and α using Data1 and Data2. The intersection points of the dashed lines are the injected parameters. Note that Data1 are the posterior parameters predicted by T-NF with Gaussian noise plus the GW signal and Data2 are the posterior parameters predicted by T-NF with Gaussian noise with blip plus the GW signal.Blip glitches exhibit a brief duration (
$ \sim 0.1 $ ms) and a frequency ranging from tens of Hz to hundreds of Hz, precisely aligning with the frequency range of BBH [105]. Their shape easily resembles that of GW signals [105, 106]. The origin of blip glitches is presently unknown, and they do not manifest in any auxiliary channels [107]. Consequently, it is probable that they will continue to be a significant component of glitches in the future.Scattered light glitches typically exhibit persistence and a low frequency. This type of noise arises when a fraction of the laser beam light scatters due to defects in the detector mirror or excessive ground motion, subsequently recombining with the main beam [48, 108]. Although its occurrence diminishes with advancements in the manufacturing processes [40], it tends to escalate with increased sensitivity. Consequently, achieving complete elimination in the future is likely to be challenging.
In our approach, we utilized data with a duration of 2 s. Considering the higher accuracy in determining the merger time during signal search [109, 110], we held the GPS time of the merger relative to the center of the Earth fixed at
$ t_0=1.8 $ s and then projected it onto the detector based on the corresponding parameters. Leveraging the work of Alvarez-Lopez et al. [111], who introduced a model capable of concurrently identifying glitches and GW signals in the data, we conducted separate training for each glitch type. To replicate the coincidence of the glitch and the merger moment, we injected glitches at a temporal distance of (-0.1 s, +0.1 s) from the merger moment. The time strain data can be written as$ s(t)=h(t)+n(t), $

(1) where
$ h(t) $ is the GW signal and$ n(t) $ is the background noise (including the glitch). The specific time strain is shown in Fig. 3.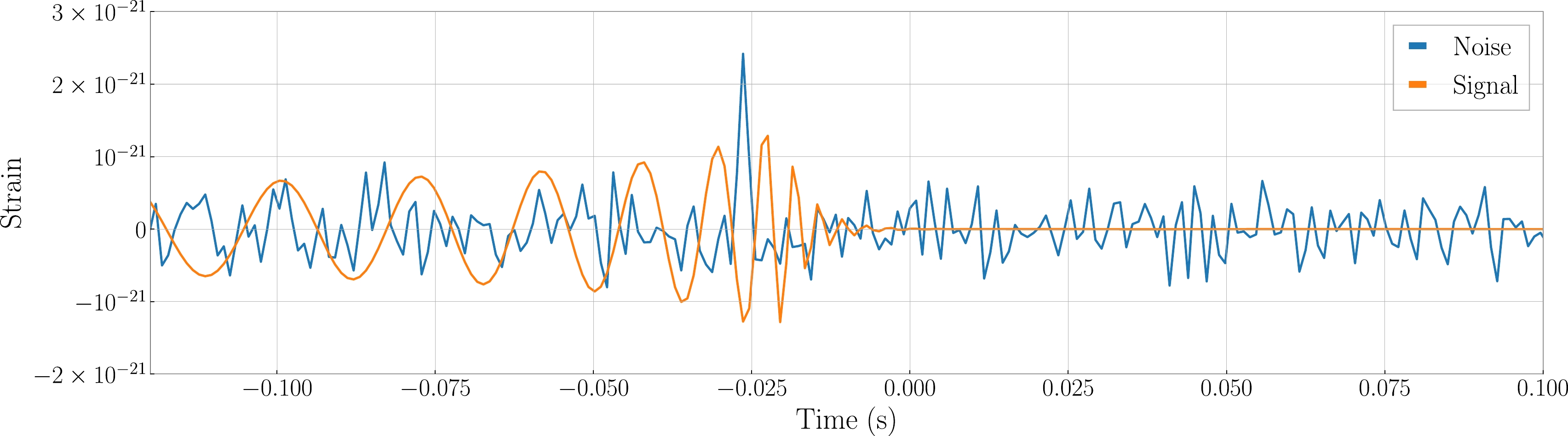
Figure 3. (color online) Time-domain strains of noise and GW signal. Here, the noise strain data is adopted from LIGO Hanford noise and the GW signal is generated based on the GW150914-like event. Note that the blip is injected at
$ t_0 - 30 $ ms of the GW signal (this is a situation depicted in Figure 3 of Ref. [42]).Referring to Hourihane et al. [68], glitches have a more pronounced impact on high-quality systems compared with on low-quality systems. Consequently, this study primarily focuses on higher mass BBH systems. Several representative parameters were considered, and the expectation is that our TTSF-NF will demonstrate applicability to other parameter sets as well. Specific parameters are detailed in Table 1, where
$ f_{\max}<512 $ Hz, and events with$ 8<{\rm{SNR}}<32 $ were exclusively selected. Given the substantial amount of existing observational data, we employed real Hanford noise containing glitches, calibrated according to Gravity Spy. The noise in other detectors corresponds to the glitch-free segments obtained from Gravitational Wave Open Science Center (GWOSC) [112]. Adhering to the Nyquist sampling law, the data's frequency only needs to exceed 2 times the value of$ f_{\max} $ ; hence, we downsampled the data to 1024 Hz. We introduced the GW signal into the noise, subsequently whitening it to derive the simulated time-domain data.Parameter Uniform distribution Chirp mass $ {\cal{M}}_{{\rm{c}}}\in[25.0, 62.5] M_{\odot} $ 

Mass ratio $ q\in [0.5, 1] $ 

Right ascension $\alpha\in[0,\, 2\pi]\; {\rm rad}$ 

Declination $\delta\in[-\pi/2, \pi/2] \; {\rm rad}$ 

Polarization angle $\psi\in[0,\, 2 \pi] \; {\rm rad}$ 

Luminosity distance $ d_{{\rm{L}}}\in[300, 3000] {\rm{Mpc}} $ 

Table 1. Distribution of simulated GW waveform parameters. Note that other parameters not mentioned are set to zero for simplicity.
The spectrogram utilized in this study was generated through the Q-transform [113], a modification of the short Fourier transform. It maps the time-frequency plane with pixels of constant Q (quality factor) by employing an analysis window whose duration is inversely proportional to the frequency. Recognizing the necessity for real-time data analysis, the spectrogram's resolution is constrained to maintain efficiency. To accommodate TTSF-NF's requirements, time and frequency were divided into 200 bins to achieve the necessary image size. The observational data d input to TTSF-NF consists of both time strain data and the spectrogram. All these steps were implemented using
$ \mathtt{PyCBC} $ [114], with the BBH waveform modeled using IMRPhenomPv2 [115]. -
The backbone of TTSF-NF is based on the normalizing flow (NF) [86], a generative model. The fundamental concept of NF involves providing a reversible transformation
$ f_d $ for each observation data d, thereby converting the simple base distribution into a more intricate posterior distribution. The pivotal aspect of this network lies in the reversibility of the transformation and the straightforward computation of the Jacobian matrix. Currently, NF has found extensive application in GW signal processing [90, 104, 116–120].The NF can be expressed by the following formula [86]
$ q(\theta \mid d)=\pi\left(f_d^{-1}(\theta)\right)\left|{\rm{det}} J_{f_d}^{-1}\right|. $

(2) The basic distribution
$ \pi(u) $ can, in principle, be arbitrary. However, for ease of sampling and density evaluation, it is often chosen to be a standard multivariate normal distribution with the same dimension D as the sample space. In practice, Eq. (2) can be continuously applied to construct arbitrarily complex densities [86]$ f_d(u)=f_{d, N}\circ f_{d, N-1}\circ \dots \circ f_{d, 1}(u), $

(3) where
$ f_{d, i}(u)\; (i=1, \dots , N) $ represents a block of the NF. This approach is referred to as neural posterior estimation (NPE). The objective of NPE is to train a parameter conditional distribution that approximates the true posterior distribution. This task translates into an optimization problem with the aim of minimizing the expected Kullback-Leibler (KL) divergence [121] between these two distributions.The loss of NF can be written as the expected value (over d ) of the cross entropy between the true and model distributions [122]
$ L=\mathbb{E}_{p(d)}\left[{\rm{KL}}\left(p(\theta \mid d) \| q(\theta \mid d)\right)\right]. $

(4) On a minibatch of training data of size N, we approximate [116]
$ L \approx-\frac{1}{N} \sum\limits_{i=1}^N \log q\left(\theta^{(i)} \mid d^{(i)}\right). $

(5) It is evident that the training of NF necessitates only the parameters corresponding to each data point without making any assumptions. This constitutes a likelihood-free method, eliminating the need for data modeling. Hence, it is well-suited for non-Gaussian and other challenging model scenarios.
In this study, we employed a currently more potent flow known as the neural spline flow (NSF) [123]. The fundamental concept behind NSF revolves around a fully differentiable module founded on monotonic rational-quadratic splines. Specifically, it consists of a series of coupling transforms. For n-dimensional data, the coupling transform maps the input vector x (for the
$ (i+1) $ th block,$ x=f_{d, i}\circ \dots \circ f_{d, 1}(u) $ ) to the output y in the following way [116, 120].1. Divide the input x into two parts,
$ x = \left [x_{1:m}, x_{m+1:n}\right ] $ where$m < n.$ 2. Input
$ x_{1:m} $ and the results output by the preceding neural network based on the input data into another neural network (specifically, the residual neural network) to obtain the vector α.3. For each
$ \alpha_{i} $ ($ i = m, ... , n $ ), one can construct the invertible function$ g_{\alpha_ {i}} $ for computing$ y_{i}= g_{\alpha _{i}} (x_{i}) $ .4. Set
$ y_{1:m} = x_{1:m} $ .Finally, return
$ y = [y_{1:m}, y_{m+1:n}] $ . The neural spline coupling transform, meanwhile, treats each output as a monotonically increasing segmented function, and by putting the abovementioned$ \alpha_ {i} $ through a series of operations one can obtain the knots$ \left \{ \left ( u_{i}^{(k)}, c_{i}^{(k)} \right ) \right \} _{k=0}^{K} $ and the positive-valued derivatives$ \left \{ \delta_{i}^{(k)} \right \} _{k=0}^{K} $ , which can be expressed in terms of interpolating rational quadratic (RQ) functions; these RQ samples are differentiable and have analytic inverses, so that they satisfy the properties required for coupled transformations. The NSF directly controls knots and derivatives by adjusting the residual network. -
In the ongoing fourth LIGO-Virgo observing run (O4), a total of four detectors are in operation. Given the temporal correlation between signals from different detectors, the data dimension is substantial, leading to some redundancy. Consequently, a prevalent approach for data processing (feature extraction) involves the utilization of multi-input machine learning [90]. In this context, we employed the front-end residual net (ResNet) to extract features from the data d.
In this section, we outline the architecture of the ResNet-50 [124] and employed the normalizing flow model. Two distinct networks, namely 1D ResNet-50 and 2D ResNet-50, were utilized to handle the input time strain and its spectrogram, respectively. Their outputs were then combined into a unified 1D vector.
ResNet-50, a 50-layer deep network, incorporates a unique feature known as skip connections. These connections link the output of one layer to another by bypassing intermediate layers. Combined with these skip connections, the layers form residual blocks, enhancing the appropriateness of the initial weights by enabling the network to learn residuals, with the output typically approaching 0. The activation function for each residual block is rectified linear units (ReLU), effectively capturing complex representations and addressing the vanishing gradient problem.
An innovative aspect of our approach involves the addition of a dropout layer with a value of 0.2 after each activation function within the ResNet. This strategic inclusion mitigates the risk of overfitting and diminishes the network's reliance on input features, potentially enhancing its suitability for processing data containing glitches.
For the subsequent normalizing flow model, we employed the ReLU activation function with the hidden layer sizes set to 4096, 9 flow steps, 7 transform blocks, and 8 bins.
In this study, our focus centered on testing events resembling GW150914, which is a representative event. Consequently, we constructed a two-detector network, although the network's applicability extends to scenarios with four or more detectors. The specific structure of the front-end ResNet is detailed in Tables 2 and 3, while the network's specific architecture is illustrated in Fig. 4. In cases in which only the time strain or spectrogram was input for comparison, the corresponding network was omitted accordingly. The network employed in this study was implemented using
$\mathtt{PyTorch}$ [125] and$\mathtt{Lampe}$ [126]. Figures were generated using$\mathtt{Matplotlib}$ [127] and$\mathtt{ligo.skymap}$ [128].Layer name Output size Architecture Input layer (2048, 2) − Conv1 (1024, 64) 7, 64, stride 2 MaxPooling (512, 64) 3 max pool, stride 2 Conv2_x (256, 256) $ \left[\begin{array}{l} {1, 64 }\\ {3, 64 }\\ {1, 256 } \end{array} \right]\times 3 $ 

Conv3_x (128, 512) $ \left[\begin{array}{l} { 1, 128} \\ {3, 128 }\\{1, 512} \end{array}\right] \times 3 $ 

Conv4_x (64, 1024) $ \left[\begin{array}{l} {1, 256} \\ {3, 256 } \\{1, 1024} \end{array}\right] \times 3 $ 

Conv5_x (32, 2048) $ \left[\begin{array}{l} {1, 512} \\ {3, 512 }\\ {1, 2048 }\end{array}\right] \times 3 $ 

Flatten (2048) − Table 2. The architecture of the ResNet model for time-domain strain data in the two-detector network. The first column shows the name of the used layer. The second column shows the dimensions of the output data obtained by the corresponding layer. The third column shows the specific structure of each layer, with labels a and b denoting the one-dimensional residual block. Here, each filter size is denoted by a, and the output channel is represented by b. “stride c” means that the stride of the convolution or pooling layer is c.
Layer name Output size Architecture Input layer (200, 200, 2) − Conv1 (100, 100, 64) Cov2D(7 $ \times $ 7, 64), stride 2

MaxPooling (50, 50, 64) 3 $ \times $ 3 max pool, stride 2

Conv2_x (25, 25, 256) $ \left[\begin{array}{l} { 1\times 1, 64 }\\{3\times 3, 64}\\{1\times 1, 256 }\end{array}\right]\times 3 $ 

Conv3_x (13, 13, 512) $ \left[\begin{array} {l} {1\times 1, 128}\\{3\times 3, 128}\\{1\times 1, 512} \end{array}\right]\times 3 $ 

Conv4_x (7, 7, 1024) $ \left[\begin{array}{l} {1\times 1, 256}\\{3\times 3, 256}\\{1\times 1, 1024} \end{array}\right] \times 3 $ 

Conv5_x (4, 4, 2048) $ \left[\begin{array}{l} { 1\times 1, 512}\\{3\times 3, 512}\\{1\times 1, 2048 }\end{array}\right]\times 3 $ 

Flatten (2048) − Table 3. Same as Table 2, but the filter size is
$ a\times a $ .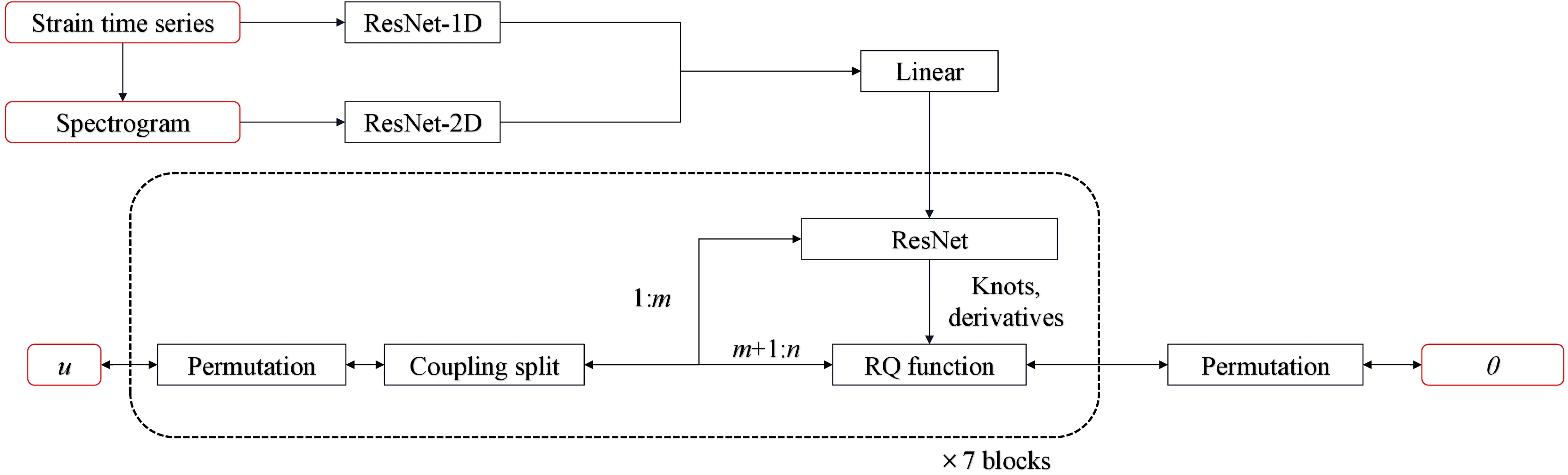
Figure 4. (color online) The workflow of TTSF-NF. The input data comprises 2-second time strain data and a spectrogram. The data traverse through the different ResNet-50 network constructed using 1D convolutional layers and 2D convolutional layers, respectively. The features extracted from the two ResNet-50 models are subsequently merged into a 1D feature vector. This feature vector is then employed as a conditional input for the normalizing flow, generating samples from the base distribution and transforming them into the posterior distribution.
Throughout the training process, we iteratively generated data by sampling the prior distributions of the events and obtaining a new noise realization for each data frame. This approach serves to augment the number of training sets and minimizes the risk of NPE producing overly confident or excessively conservative posterior distributions [129]. The AdamW optimizer [130] was employed with a learning rate set to 0.0001, a batch size of 200, and a learning rate decay factor of 0.99. For initializing the network parameters with initial random values, the "Xavier" initialization [131] was applied. This initialization method aims to maintain an appropriate scale for the weights during both forward and backward propagation, mitigating issues such as gradient disappearance or explosion. Its design principle involves initializing weights to random values that adhere to a specific distribution, ensuring consistency in the input and output variances.
Training incorporated an early stopping strategy to achieve convergence and prevent overfitting. The network underwent approximately 16 days of training on a single NVIDIA GeForce RTX A6000 GPU with 48 GB of memory.
-
Before drawing specific inferences, it is crucial to assess the reliability of the method's results. This is achieved by conducting the Kolmogorov-Smirnov (KS) test [132] to compare the one-dimensional posterior distributions generated by the TTSF-NF outputs. Taking blips as an example, Hanford's O3b data comprises a total of 1437 entries with
$ {\rm{SNR}}>12 $ , and 1300 of these were selected for training. Subsequently, KS testing was performed using 100 noise-injected simulated waveforms containing blips, which were not part of the training process. Figure 5 illustrates the construction of a probability-probability (P-P) plot based on 200 simulated datasets. For each parameter, we calculated the percentile value of the true value within its marginal posterior, plotting the cumulative distribution function (CDF) of this value, which represents the range of intervals covered by the corresponding confidence interval. In a well-behaved posterior, the percentiles should be uniformly distributed, resulting in a diagonal CDF. The p-values for the KS test are provided in the figure legends, and the gray area denotes the$ 3\sigma $ confidence limit. The proximity of the CDF to the diagonal indicates the model's ability to accurately sample the posterior, confirming the reasonability of the parameter range given by this method.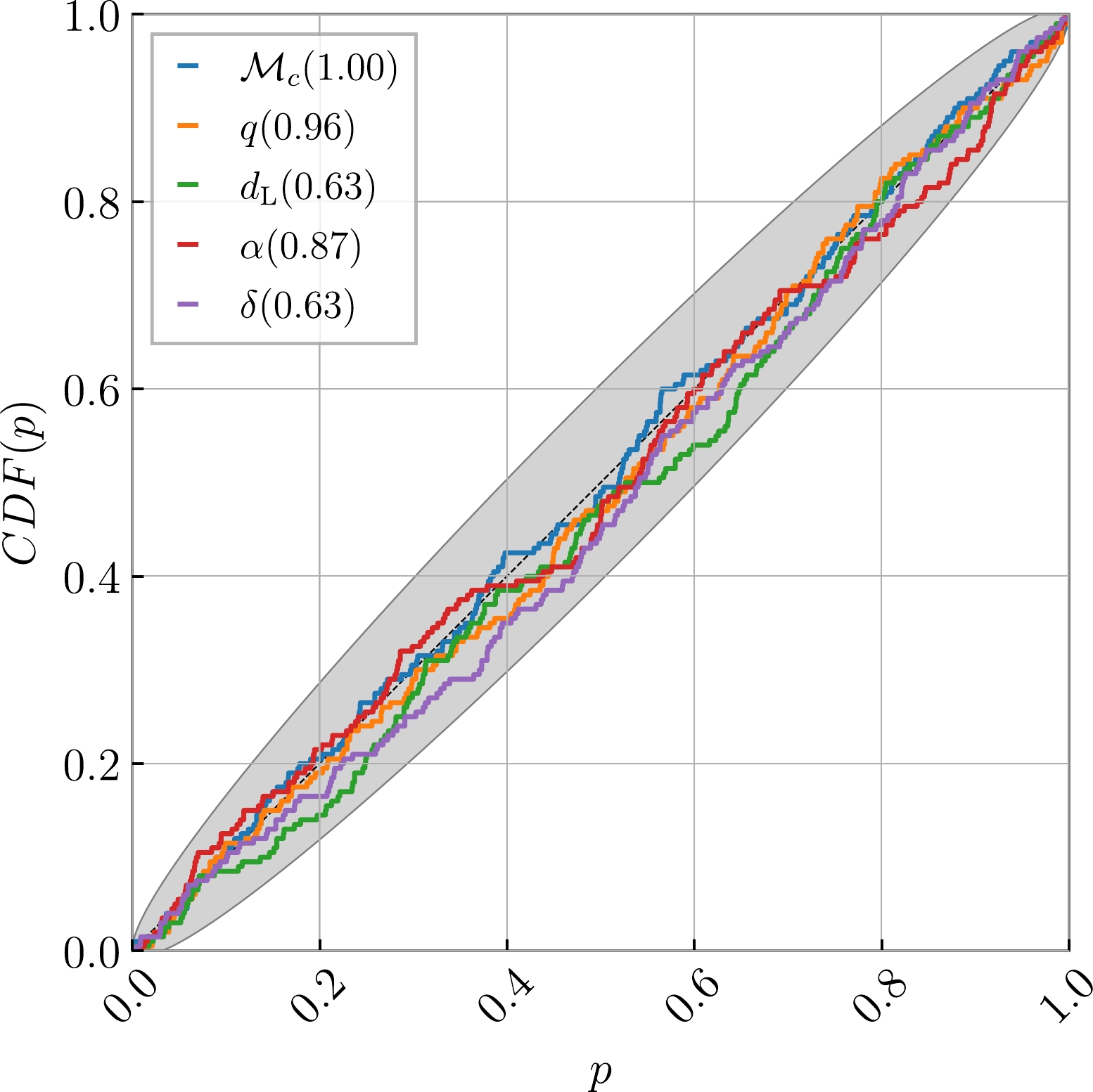
Figure 5. (color online) P-P plot for 200 simulated datasets containing blips analyzed by TTSF-NF.
Figure 6 displays the posterior distribution of an event, emphasizing our innovative approach to exploring non-Gaussian noise and proposing new solution ideas. To initially evaluate the effectiveness of this method, we compared it with the posterior distributions in the absence of glitches. Position parameter inference results from
$\mathtt{Bilby}$ [133] and the network are shown for scenarios with and without blips in the noise. The interval time chosen for this comparison, following Macas et al. [42], is ($ t_0 - 30 $ ) ms, when the blip has the most significant impact on positioning. The results indicate that TTSF-NF can avoid position errors induced by glitch-contaminated data and achieves an accuracy comparable to$\mathtt{Bilby}$ with the$\mathtt{dynesty}$ sampler [134] on glitch-free data. Although we observe a bimodal shape in the network's posterior distribution, the probability of the second peak is low and can be disregarded. This phenomenon may arise from the narrow width of ResNet and the relatively simple feature extraction [135].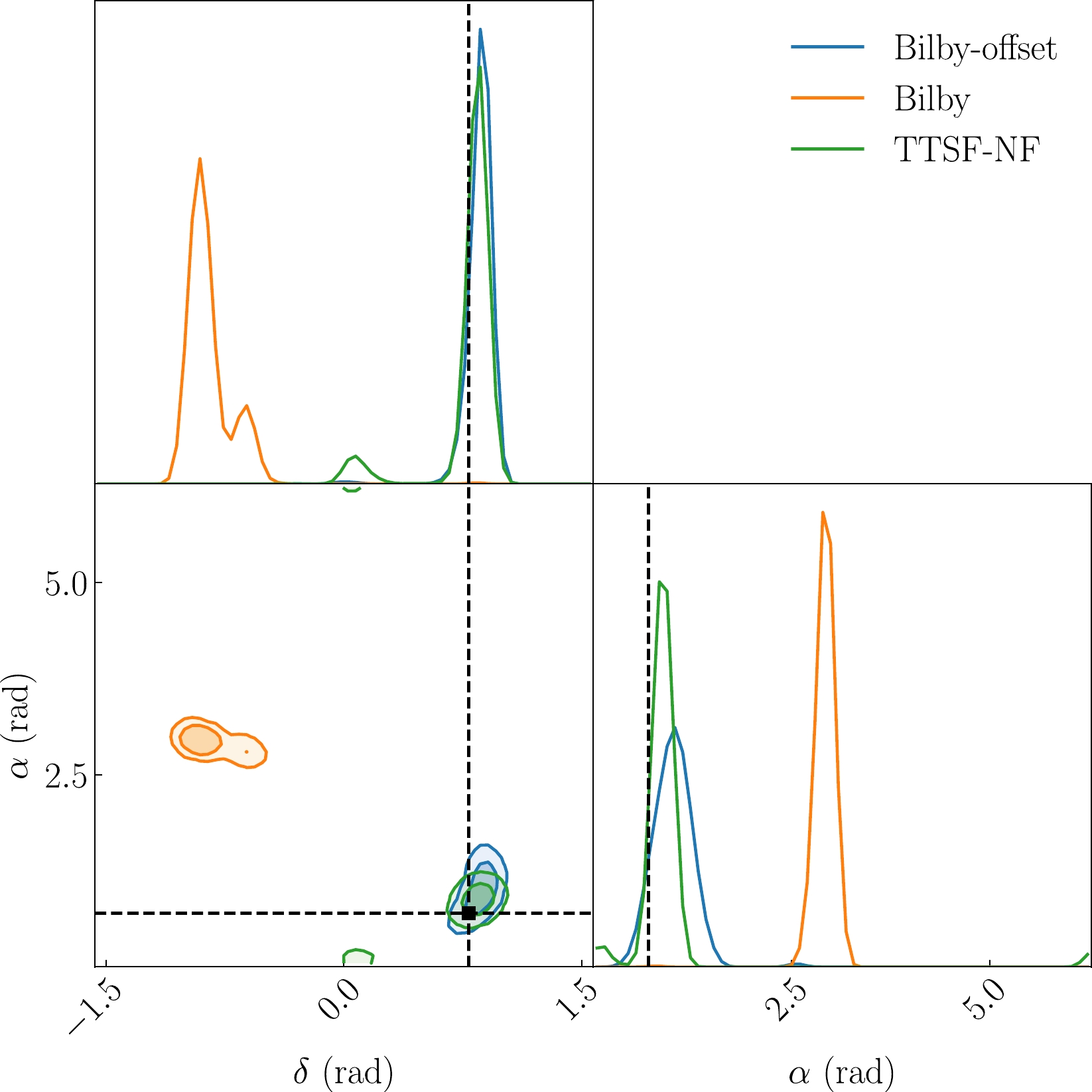
Figure 6. (color online) One- and two-dimensional marginalized posterior distributions for δ and α. The intersection points of the dashed lines are the injected parameters. Here, the Bilby-offset represents the posterior parameters predicted by
$\mathtt{Bilby}$ with noise (without blip) plus the GW signal. Bilby represents the posterior parameters predicted by$\mathtt{Bilby}$ with noise (with blip) plus the GW signal. TTSF-NF represents the posterior parameters predicted by the network with noise (with blip) plus the GW signal. -
We proceeded to investigate whether it is necessary to input both the time strain and the spectrogram. Initially, we examined the overall loss of the network, as depicted in Fig. 7. The loss comparison suggests that TTSF-NF exhibits a better performance, although T-NF still performs reasonably well. However, these losses are based on the 1300 blips in the training set. To ascertain if the network has genuinely learned the characteristics of blips, we evaluated its generalization performance on the remaining 100 glitches that were not part of the training set.
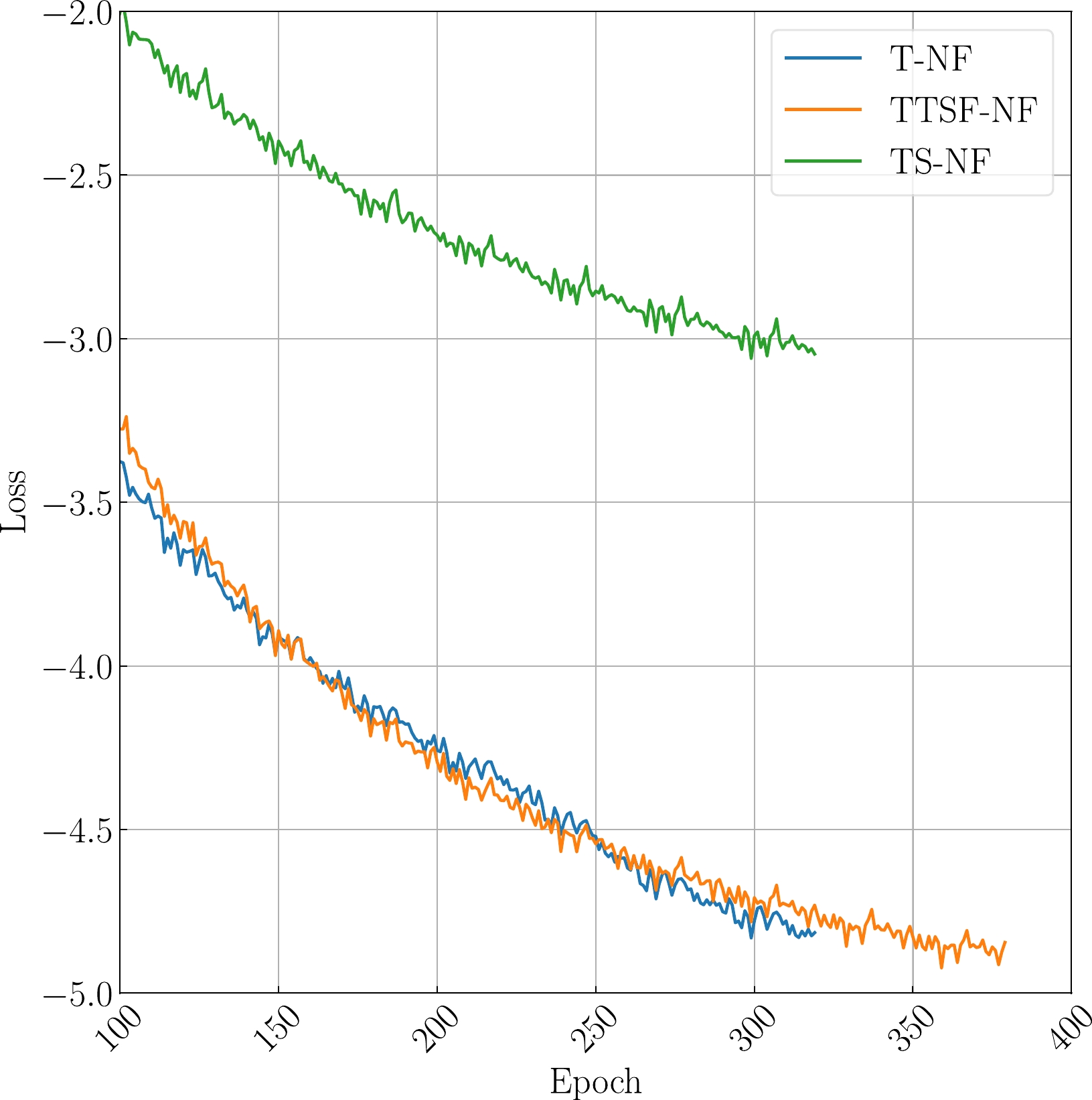
Figure 7. (color online) The loss of all different networks for each epoch. During the training process, we used 10 cycles of early stops to ensure that each network could reach the optimal. Here, T-NF represents the loss of the network using only time strain. TTSF-NF represents the loss of the network using both time strain and a spectrogram. TF-NF represents the loss of the network using only a spectrogram.
For glitches not included in the training set, TTSF-NF outperforms T-NF. The overall parameter estimation performance is quantified by the determination coefficient
$ R^2 $ under the same source parameters, defined as follows:$ R^{2} =1-\frac{\sum (y_{\rm{pre}} -y_{\rm{true}})}{\sum (y_{\rm{pre}} -\bar{y} _{\rm{true}})} , $

(6) where
$ y_{\rm{pre}} $ and$ y_{\rm{true}} $ represent the variable estimates in the sample and the true value of the test sample, respectively, and$ \bar{y} _{\rm{true}} $ represents the average true value of the test sample. We calculated$ R^2 $ for 200 test datasets in our preset range for both networks. For T-NF,$ R^2=0.66 $ ; for TTSF-NF,$ R^2=0.71 $ . Therefore, incorporating both time strain and a spectrogram yields significant improvements.Figure 8 presents the specific posterior distributions, notably in α and δ. The time-spectrogram normalizing flow (TS-NF) reveals the widest posterior distribution, which is attributed to limitations in the time-frequency resolution and binning that may result in the loss of detailed information. Additionally, the posterior distribution is not significantly enhanced for T-NF. This is because the glitch's impact on the GW parameters primarily stems from temporal and frequency overlap. Consequently, TSF-NF struggles to differentiate between signal and noise information. TTSF-NF combines the strengths of both approaches. It emphasizes the contributions of different frequency components in the time series, facilitating a clearer distinction between signal and noise, while preserving time resolution as much as possible. This makes it more suitable for signal processing when the channel is contaminated by glitches. Despite the potential longer computation time required for spectrogram calculation using the Q-transform, the benefits of leveraging both representations outweigh the potential delay, particularly when considering the enhanced analytical capabilities they provide.
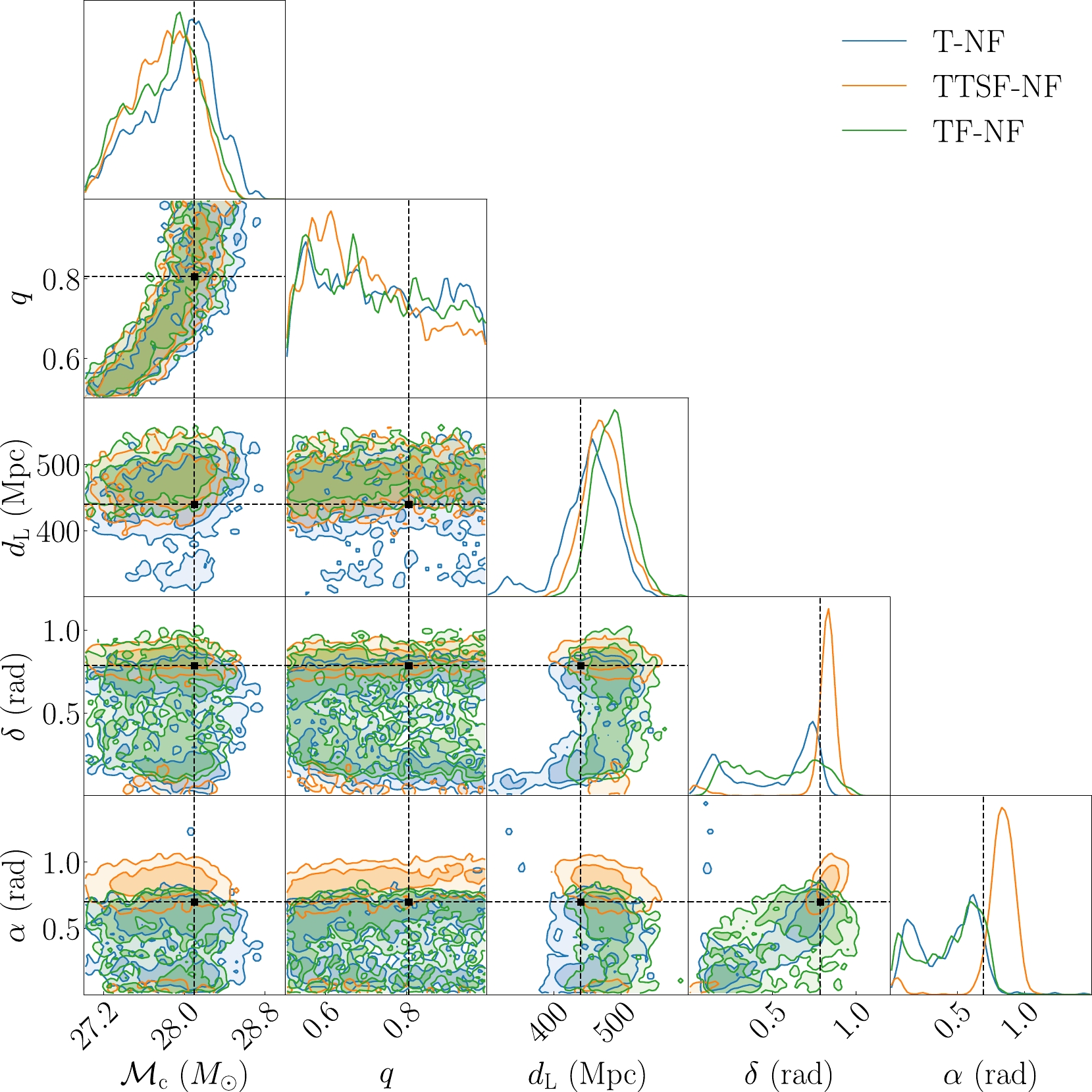
Figure 8. (color online) One- and two-dimensional marginalization of
$ {\cal{M}}_{{\rm{c}}} $ , q,$ d_{{\rm{L}}} $ , δ and α with blip for different NF estimates of the posterior distribution. The intersection points of the dashed lines are the injected parameters. Here, T-NF represents the posterior parameters predicted by the network using only time strain. TTSF-NF represents the posterior parameters predicted by the network using both time strain and a spectrogram. TF-NF represents the posterior parameters predicted by the network using only a spectrogram.The results indicate that the posterior distributions of each NF for the luminosity distance
$ d_{{\rm{L}}} $ , chirp mass$ {\cal{M}}_{{\rm{c}}} $ , and mass ratio q are similar, which might be attributed to glitch extraction. However, it is premature to conclude that glitches affect different parameters inconsistently across neural networks. Table 4 presents the specific posterior distributions after data cleansing. Our findings reveal that the network performed best when utilizing both time strain data and spectrograms, achieving an accuracy comparable to that for glitch-free data. Notably, while the network inference's posterior distribution accuracy exceeds that of the Bilby inference, this discrepancy could stem from the non-stationary nature of the noise at varying time instances.Parameter Injected value Bilby-offset Bilby T-NF TTSF-NF TS-NF ${\cal{M} }_{ {\rm{c} } } (M_{\odot})$ 

28.10 $ 27.85_{-0.47}^{+0.28} $ 

$ 28.28_{-0.53}^{+0.35} $ 

$ 27.97_{-0.86}^{+0.55} $ 

$ 27.79_{-0.66}^{+0.52} $ 

$ 27.55_{-0.76}^{+0.53} $ 

q 0.83 $ 0.72_{-0.18}^{+0.26} $ 

$ 0.67_{-0.15}^{+0.29} $ 

$ 0.72_{-0.21}^{+0.26} $ 

$ 0.69_{-0.18}^{+0.29} $ 

$ 0.71_{-0.20}^{+0.28} $ 

$d_{\rm L}(\rm Mpc)$ 

440.00 $ 423.57_{-38.89}^{+58.27} $ 

$ 426.26_{-25.04}^{+27.59} $ 

$ 453.89_{-125.52}^{+64.94} $ 

$ 468.75_{-52.80}^{+60.76} $ 

$ 456.7_{-63.11}^{+63.11} $ 

α (rad) 0.69 $ 0.84_{-0.33}^{+0.15} $ 

$ 2.89_{-0.16}^{+0.08} $ 

$ 0.46_{-0.42}^{+0.28} $ 

$ 0.83_{-0.16}^{+0.15} $ 

$ 0.36_{-0.58}^{+0.37} $ 

δ (rad) 0.78 $ 0.83_{-0.13}^{+0.03} $ 

$ -0.92_{-0.10}^{+0.32} $ 

$ 0.63_{-0.53}^{+0.17} $ 

$ 0.82_{-0.08}^{+0.07} $ 

$ 0.52_{-0.39}^{+0.40} $ 

Table 4. A comparison between previously injected parameters and parameters recovered by
$\mathtt{Bilby}$ and normalizing flow methods. The recovered values are accompanied by their$ 2\sigma $ confidence regions. Here, the Bilby-offset represents the posterior parameters predicted by$\mathtt{Bilby}$ with noise (without blip) plus GW signal. Bilby represents the posterior parameters predicted by$\mathtt{Bilby}$ using noise (with blip) plus the GW signal.The processing time for each network and the comparison with
$\mathtt{Bilby}$ are outlined in Table 5. For the spectrogram-applied method, we considered the data processing time utilizing 32 CPUs in parallel. It is evident that regardless of the method used, the processing time is significantly faster than that of the traditional method. When combined with the Q-transform time, the overall processing time is not significantly longer, indicating the continued suitability of the Q-transform. In practical applications, additional time for calibration, strain data distribution, and signal identification must be considered. The time required for these tasks averages around 0.4 s for 2 s of time strain data [136, 137]. All networks can complete processing within 2 s (the length of the data), making them suitable for real-time data processing.Sampling Method Number of posterior samples Total runtime/s Time per sample/s Bilby 2111 246.41 0.1165 T-NF 1024 0.66 0.0006 TTSF-NF 1024 1.35 0.0013 TS-NF 1024 1.13 0.0011 Table 5. A comparison of the computational time required by different methods for generating their respective samples. Note that the input data is noise (with blip) plus GW signal.
-
Given that various glitch types exhibit different distributions in time and frequency, whereby blips are typically short-term, it is crucial to demonstrate the algorithm's suitability for other glitch forms. To investigate this aspect, we chose scattered light noise for validation, aiming to determine if the method is effective for long-duration glitches. We utilized 1200 glitches for both training and testing.
Figure 9 presents the P-P plot generated from 200 simulated datasets for testing. This plot underscores the reliability of the posterior distribution produced by our network, even when the noise includes scattered noise. Specific posterior distribution details are illustrated in Fig. 10.
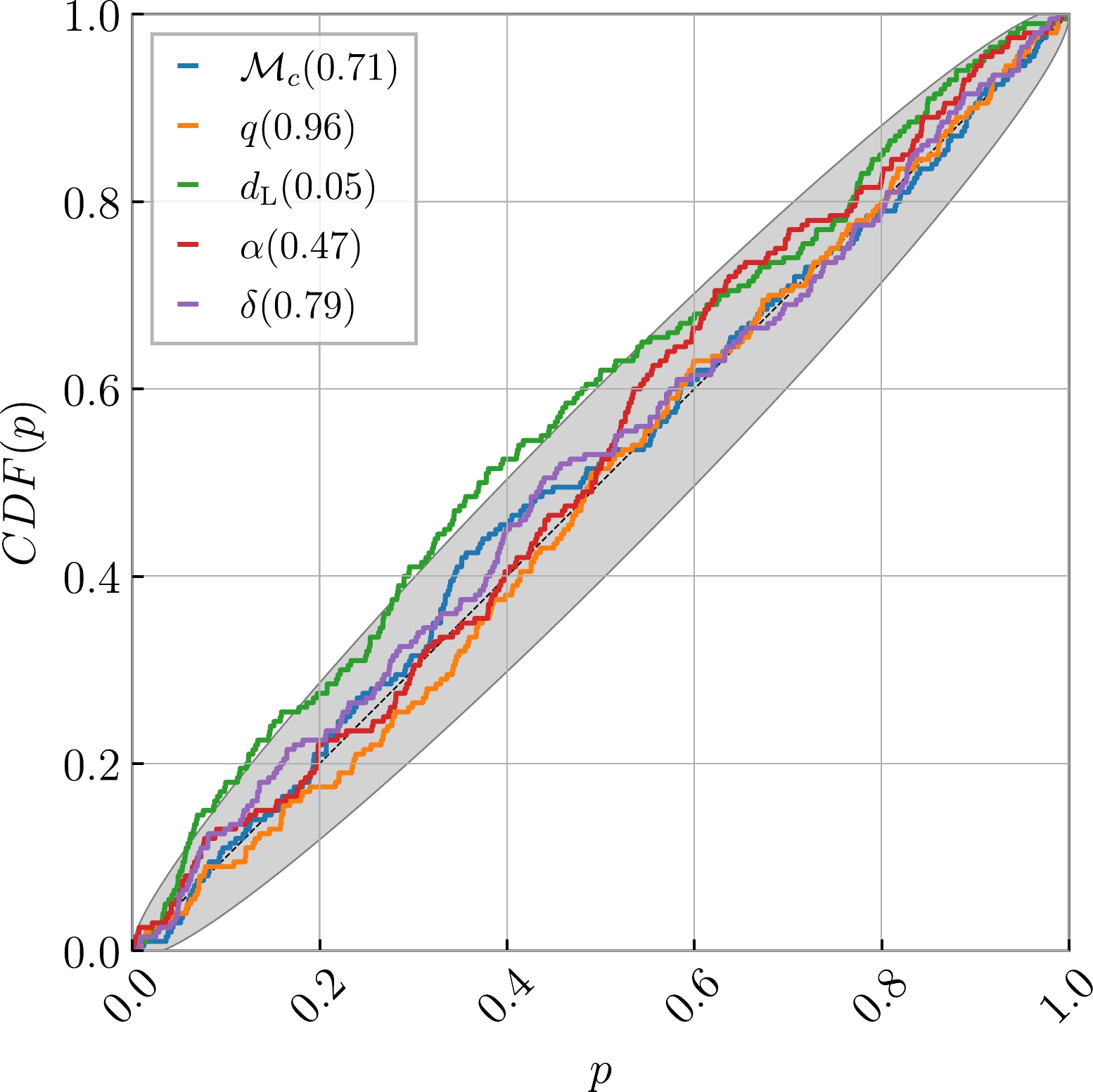
Figure 9. (color online) P-P plot for 200 simulated datasets containing scattered light noises analyzed by TTSF-NF.
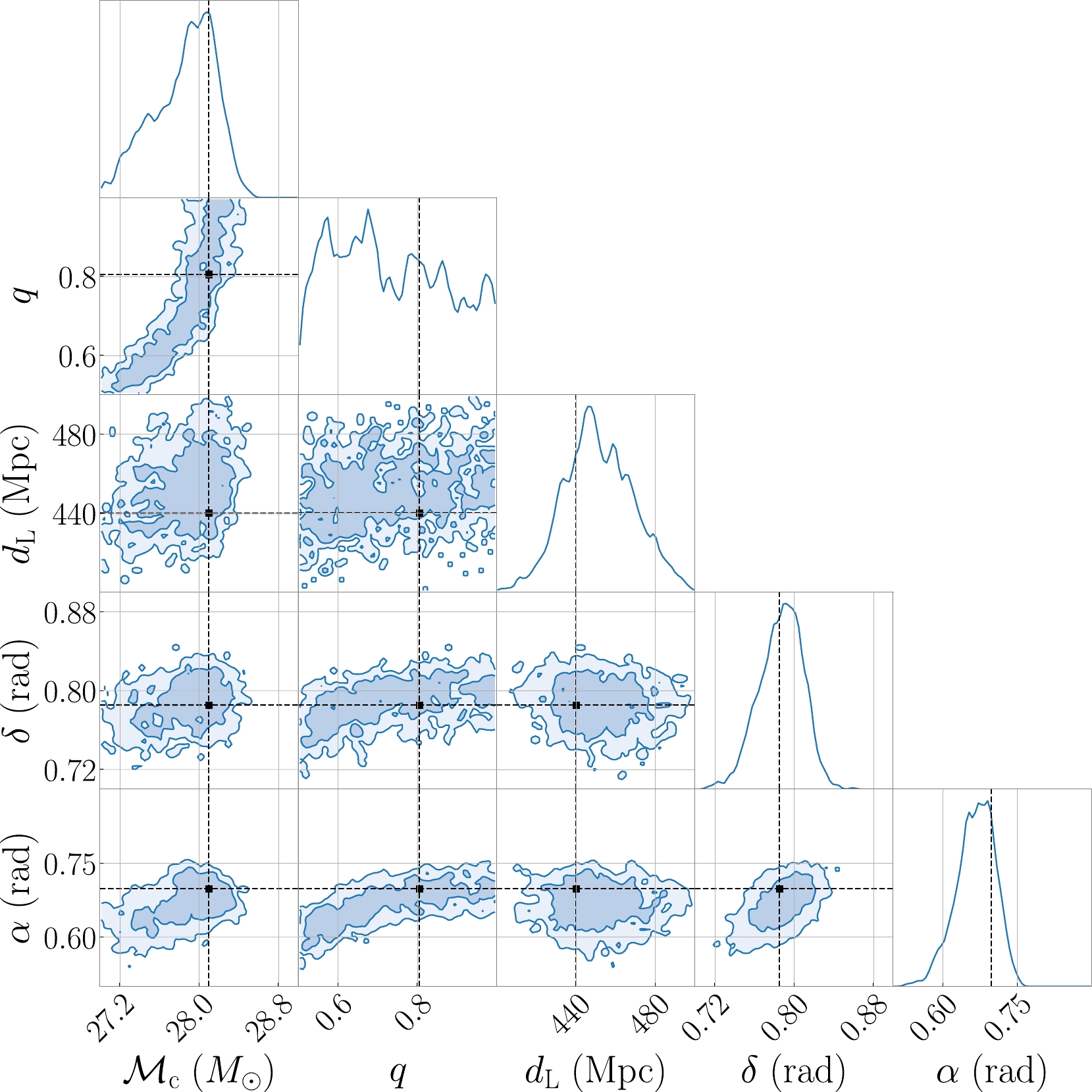
Figure 10. (color online) One- and two-dimensional marginalized posterior distributions for
$ {\cal{M}}_{{\rm{c}}} $ , q,$ d_{{\rm{L}}} $ , δ and α with scattered light noise. The intersection points of the dashed lines are the injected parameters. -
GW detectors often encounter disruptive non-Gaussian noise artifacts known as glitches. The occurrence of these glitches in proximity to GW events can significantly impact subsequent parameter estimates. Conventional deglitching methods, while effective, demand substantial computational resources, posing challenges for achieving real-time deglitching at higher frequencies of GW events in the future. This, in turn, could impede timely observations of physical phenomena, including EM counterpart observations.
In this study, we leverage TTSF-NF to expedite parameter inference when GW data are marred by glitches. This assumes critical significance for swift wave source localization and real-time analysis, particularly as the frequency of future events escalates. Our pioneering approach involves combining the high temporal resolution of the time domain with the distinct discriminability of features in the time-frequency domain, aiming for rapid and judicious parameter inference in glitch-contaminated data. Notably, our choice of the normalizing flow as a more flexible flow contributes to the success of this innovative methodology.
Specifically, our focus was on glitches with a
$ {\rm{SNR}}>12 $ , which represents one of the most prevalent glitch types in GW detectors that existing robust methods struggle to effectively process. Notably, we discovered that relying solely on the spectrogram for parameter inference is suboptimal due to resolution limitations. Although the use of only the time strain on the training set produced effects equivalent to utilizing both time strain and a spectrogram, the network relying solely on time strain struggled to effectively discriminate between features in the time domain for previously unseen glitches. The incomplete separation of these features resulted in an inferior performance compared with the network utilizing both time strain and a spectrogram. Our proposed method achieves real-time data processing, processing 2 s of data in 1.35 s. Additionally, we verified the applicability of this model to scattered light noise.The integration of the normalizing flow opens promising avenues for the future real-time processing of glitch-contaminated data. It is essential to note that the upper limit of the frequency in this study is 1024 Hz, and as the frequency of BNS mergers exceeds this threshold, with BNS remaining in the detector's sensitive range for longer than 2 s, direct migration of this network to BNS scenarios is not viable. In our subsequent work, we plan to address the BNS scenario and explore more suitable front-end network structures for better data fusion. Simultaneously, we will consider implementing methods such as Cohen's Class of Time-Frequency Representations to enhance the time-frequency domain resolution for an optimal performance.
-
This research has made use of data or software obtained from the Gravitational Wave Open Science Center (gwosc.org), a service of LIGO Laboratory, the LIGO Scientific Collaboration, the Virgo Collaboration, and KAGRA. We thank He Wang for helpful discussions.
Efficient parameter inference for gravitational wave signals in the presence of transient noises using temporal and time-spectral fusion normalizing flow
- Received Date: 2024-01-19
- Available Online: 2024-04-15
Abstract: Glitches represent a category of non-Gaussian and transient noise that frequently intersects with gravitational wave (GW) signals, thereby exerting a notable impact on the processing of GW data. The inference of GW parameters, crucial for GW astronomy research, is particularly susceptible to such interference. In this study, we pioneer the utilization of a temporal and time-spectral fusion normalizing flow for likelihood-free inference of GW parameters, seamlessly integrating the high temporal resolution of the time domain with the frequency separation characteristics of both time and frequency domains. Remarkably, our findings indicate that the accuracy of this inference method is comparable to that of traditional non-glitch sampling techniques. Furthermore, our approach exhibits a greater efficiency, boasting processing times on the order of milliseconds. In conclusion, the application of a normalizing flow emerges as pivotal in handling GW signals affected by transient noises, offering a promising avenue for enhancing the field of GW astronomy research.



 DownLoad:
DownLoad: